MAGRPO:用多智能体强化学习训练真正会协作的 LLM
Why Independent Fine-Tuning Fails When LLMs Need to Collaborate
多 Agent LLM 系统现在很常见:一个负责规划,一个负责写代码,一个负责审查,一个负责总结。听起来像一个高效团队,但现实里经常出现一个问题:多个 LLM 被 prompt 临时组织起来,并不等于它们真的学会了协作。
Bohrium 这篇文章解读的 MAGRPO,全称是 Multi-Agent Group Relative Policy Optimization,它试图把“LLM 如何协作”从 prompt 工程问题,重新建模为一个多智能体强化学习问题。核心思想是:不要只靠提示词让多个模型“看起来像在配合”,而是在训练阶段用共享奖励让它们学会共同优化一个团队目标。(Bohrium)
1. 为什么普通多 Agent Prompt 容易失败?
很多多 Agent 系统本质上还是测试时编排:模型不变,只是在推理时通过 debate、discussion、review、sequential pipeline 等方式让它们交换输出。问题是,这些 Agent 并没有被训练成一个团队,它们只是被 prompt 临时要求“合作”。原论文指出,这类方法容易出现沟通低效、角色遵循不稳定、错误信息互相传播,以及 prompt/角色设计不清晰等问题。(ar5iv)
另一类方法是独立微调每个 Agent,比如给“规划者”“执行者”“审查者”分别设计奖励。但这又带来两个难点:
第一,奖励设计很复杂。你需要手动判断每个角色应该拿什么奖励,但协作任务的成功往往来自整体效果,很难拆成每个 Agent 的独立贡献。
第二,多智能体环境是非平稳的。当一个 Agent 的策略更新后,另一个 Agent 面对的“环境”也变了。这会让每个模型都在一个不断变化的环境里学习,收敛会更困难。原论文也明确批评了这类独立学习方法在非平稳环境下缺少可靠保证。(ar5iv)
所以,MAGRPO 要解决的不是“怎么写更好的多 Agent Prompt”,而是:
能不能让多个 LLM 在训练时就围绕同一个团队目标学习,并在推理时仍然保持并行、高效、去中心化执行?
2. MAGRPO 的基本思路:训练时集中,执行时分散
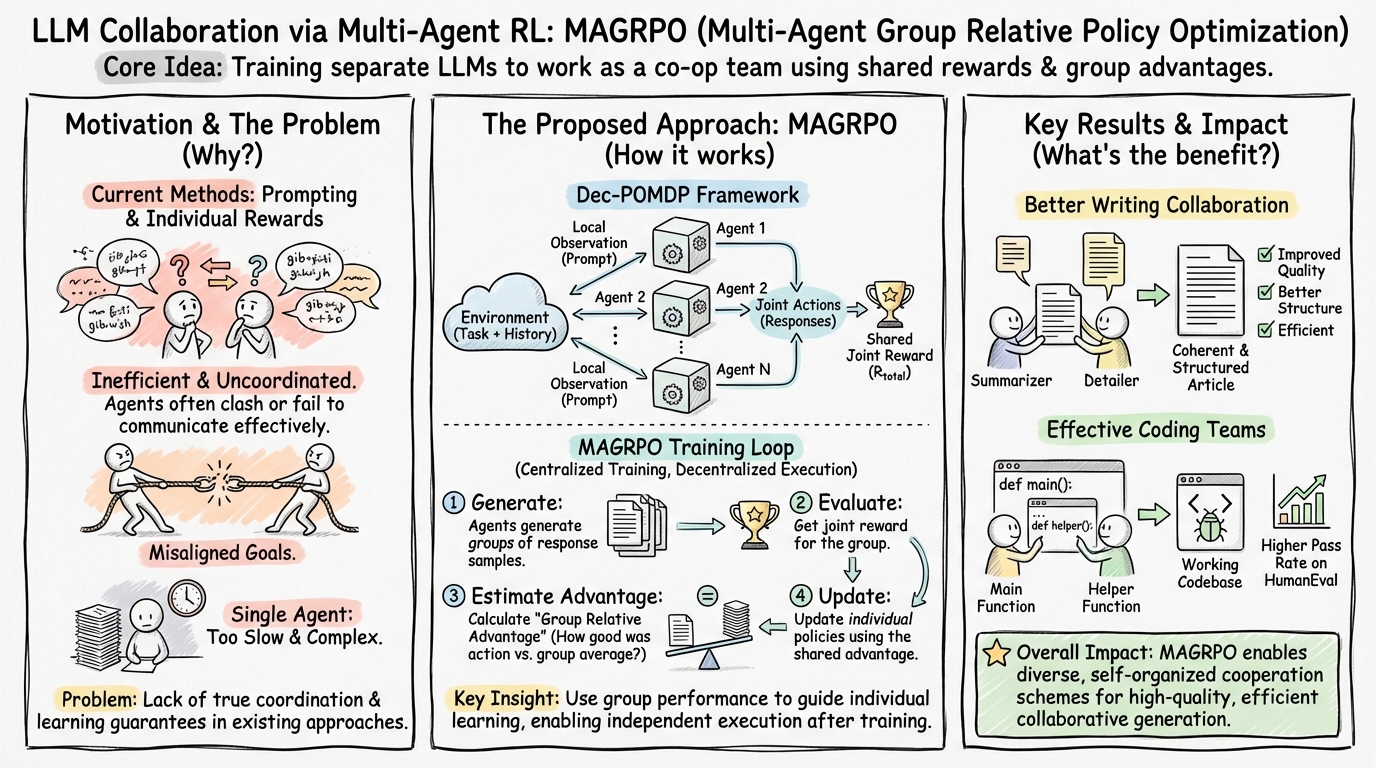
LLM Collaboration via Multi-Agent RL: MAGRPO
MAGRPO 把 LLM 协作建模为 Dec-POMDP,也就是 Decentralized Partially Observable Markov Decision Process,去中心化部分可观测马尔可夫决策过程。
这个名字很长,但直观理解并不复杂:
多个 Agent 共享一个最终目标,但每个 Agent 只能看到自己的局部输入。比如在协作写作中,一个 Agent 负责写摘要,另一个负责补充细节;在协作编程中,一个 Agent 写辅助函数,另一个 Agent 写主函数。它们不能直接读取彼此的内部状态,只能通过任务输入、历史输出或环境反馈间接协作。原论文把状态、局部观察、自然语言响应、共享奖励和回合限制都放进 Dec-POMDP 框架里,用它来描述 LLM 协作任务。(ar5iv)
MAGRPO 采用的是一种 Centralized Training, Decentralized Execution 的思路:
训练时,系统可以从整体结果计算一个共享奖励,判断多个 Agent 的联合输出好不好。
执行时,每个 Agent 不需要中心控制器逐步指挥,而是根据自己的局部上下文独立生成,多个 Agent 可以并行工作。
这点很关键。很多多 Agent 系统慢,是因为它们需要一轮轮对话、互相等待、反复汇总。MAGRPO 想要的是:协作能力在训练中学进去,推理时少沟通甚至不沟通,也能自然配合。
3. MAGRPO 和 GRPO 的关系
MAGRPO 是对 GRPO,也就是 Group Relative Policy Optimization 的多智能体扩展。
普通 GRPO 的一个重要思想是:不一定要训练一个额外的 value model,而是可以生成一组候选输出,然后用组内相对表现估计 advantage。MAGRPO 把这个思想扩展到多个 Agent 的联合输出上。
训练流程可以粗略理解为:
- 从数据集中采样一个任务;
- 多个 Agent 根据自己的局部 prompt 分别生成多组响应;
- 把多个 Agent 的输出组合成联合动作;
- 环境或奖励模型给这些联合输出打一个共享奖励;
- 用组内平均表现作为基准,计算每组联合输出的相对优势;
- 用这个优势去更新每个 Agent 的策略。
原论文特别强调,MAGRPO 不使用显式 value model,而是通过一组 Monte Carlo 样本估计当前状态的期望回报,从而获得一种集中式的 advantage 估计,再分别更新每个 Agent 的策略。(ar5iv)
这带来的好处是:它既不像传统 CTDE 方法那样依赖巨大的 centralized critic,也不像完全独立训练那样丢掉团队层面的反馈。它用“共享奖励 + 组内相对优势”在两者之间做了一个折中。
4. 实验结果:协作不是多聊几轮,而是训练出来的
原文和论文主要展示了两个方向的实验:协作写作和协作编程。
4.1 协作写作
写作实验包括 TLDR 摘要和 arXiv 摘要扩写。系统使用两个 Qwen3-1.7B Agent:一个负责更短的核心摘要,另一个负责更详细的总结或扩写。奖励由结构、风格一致性、逻辑连贯性等指标组合而成。(ar5iv)
结果很有意思:在 TLDR 任务上,MAGRPO 的速度是 202.3 tokens/s,响应时间约 2.1 秒;单个 Qwen3-4B 模型是 64.1 tokens/s,响应时间约 6.6 秒。也就是说,两个小模型并行协作,速度接近单个较大模型的 3 倍。更重要的是,MAGRPO 在 TLDR 上的 normalized return 达到 94.5%,明显高于 one-round discussion 的 22.3% 和 sequential generation 的 21.7%。(ar5iv)
这说明一个问题:多 Agent 的关键不是让模型“多讨论”,而是让它们在训练中学会稳定分工。
4.2 协作编程
编程实验里,论文让两个 Qwen2.5-Coder-3B Agent 协作生成 Python 函数:一个生成辅助函数,另一个生成主函数。它们的输出会被拼接成完整代码,并通过结构完整性、语法正确性、单元测试通过率和协作质量来评估。(ar5iv)
在 HumanEval 和 CoopHumanEval 上,MAGRPO 的结果整体优于 naive concatenation、sequential pipeline 和 one-round discussion 等 prompt-based baseline。尤其在 CoopHumanEval 这种更适合协作拆解的数据集上,multi-turn MAGRPO 的总回报达到 88.1%,明显高于其他 baseline。(ar5iv)
这里还有一个细节很重要:普通 HumanEval 中很多题本身并不适合拆成两个 Agent 协作,比如一个很短的原子函数。论文因此构造了 CoopHumanEval,让任务更具备协作结构。结果显示,当数据本身更适合分工,MAGRPO 的训练效果更稳定,回报也更高。(ar5iv)
这对工程落地很有启发:多 Agent 不应该强行套在所有任务上,它更适合那些天然可以模块化、并且有清晰反馈信号的任务。
5. MAGRPO 学到的不是固定流程,而是协作模式
在协作编程中,论文观察到 MAGRPO 会自然形成几类合作模式:
一种是 fallback。辅助函数尝试完成核心逻辑,主函数保留一套兜底逻辑,避免辅助函数出错导致整体失败。
一种是 decorator。辅助函数完成主要逻辑,主函数负责边界处理、格式整理或额外健壮性增强。
还有一些更主动的模式,比如主函数像 coordinator 一样拆解问题,或者辅助函数像 strategy filter 一样引导主函数处理特定情况。论文认为,这些合作模式是在简单共享奖励下自然涌现出来的。(ar5iv)
这也是 MAGRPO 最值得关注的地方:它不是写死一个 workflow,而是让多个 Agent 在奖励驱动下学出适合任务的协作策略。
6. 它适合什么场景?
MAGRPO 最适合下面这类任务:
任务可以拆成多个相对稳定的角色,比如摘要/扩写、主函数/辅助函数、前端/后端、规划/执行。
任务有可自动验证或半自动验证的奖励信号,比如单元测试、格式检查、结构约束、风格一致性、集成测试结果。
推理速度很重要,希望多个小模型并行执行,而不是一个大模型串行完成所有工作。
任务会反复出现,值得通过训练把协作模式沉淀进模型权重,而不是每次都靠 prompt 临时协调。
原文也提到,MAGRPO 可以启发软件开发、创意写作、隐私保护型诊断、多角色金融分析等应用。但其中很多属于长期设想,真正落地仍然依赖可验证奖励、数据质量和安全控制。(Bohrium)
7. 局限性:这还不是“通用 Agent 团队训练法”
MAGRPO 的局限也很明显。
首先,目前实验主要集中在短 horizon 任务,比如摘要、扩写、函数级代码生成。长周期任务,例如完整软件项目、长篇小说、多日研究流程,可能仍然需要显式通信、共享记忆和阶段性规划。Bohrium 原文也指出,当前结果还不能证明这种隐式协调能稳定扩展到极长上下文场景。(Bohrium)
其次,奖励设计并没有消失,只是从“给每个 Agent 手工设计奖励”变成了“给联合输出设计共享奖励”。在代码任务里,单元测试是天然反馈;但在开放式产品设计、复杂研究、商业决策中,什么是好结果并不总是容易量化。
第三,MAGRPO 的优势和数据结构强相关。论文中 CoopHumanEval 比原始 HumanEval 更适合协作,因此效果更好。这说明训练多 Agent 时,数据集本身是否具备可分工结构非常关键。(ar5iv)
最后,论文中的 baseline 多数仍是 prompt-based 方法,而不是其他强力 fine-tuned 多 Agent 方法。因此,MAGRPO 证明了“训练协作优于临时 prompt 协作”,但还需要和更多多智能体训练算法进一步比较。
8. 对 Agent 工程的启发
MAGRPO 给 Agent 系统设计带来的最大启发是:协作不应该只停留在 prompt 编排层,而应该进入训练目标层。
今天很多 Agent 框架的核心是“搭流程”:谁先说,谁后说,谁 review,谁总结。这个方向当然有用,但它更像是在组织一群没有磨合过的人开会。MAGRPO 的思路更像是训练一支长期配合的团队:每个成员不需要每一步都开会,但知道自己在什么位置、该如何输出、如何和别人的结果形成整体最优。
对工程实践来说,可以总结成三句话:
第一,不要迷信“多 Agent = 更强”。如果没有共享目标和反馈信号,多 Agent 可能只是更贵、更慢、更难 debug。
第二,优先选择有明确验证信号的任务做多 Agent 训练,比如代码生成、数据处理、报告生成、结构化写作。
第三,小模型并行协作可能比单个大模型串行执行更高效,但前提是这些小模型经过面向协作的训练,而不是只靠 prompt 分工。
结语
MAGRPO 的价值不只是提出了一个新算法,而是把多 Agent LLM 的问题重新摆正了:
多 Agent 系统真正难的不是让模型互相说话,而是让它们围绕同一个目标形成稳定、可泛化、可并行执行的协作策略。
如果未来 Agent 系统要从 demo 走向真实生产环境,光靠 prompt orchestration 可能不够。像 MAGRPO 这样的多智能体强化学习方法,可能会成为训练“专业 AI 团队”的关键路径之一。
参考:Bohrium 原文解读、arXiv 论文《LLM Collaboration With Multi-Agent Reinforcement Learning》,以及作者开源的 CoMLRL 框架。CoMLRL 提供了用于训练多个 LLM 协作的 MARL 算法实现,并包含 writing、coding、Minecraft 等环境和 benchmark。(Bohrium)