Fine-tuning to follow instructions 2. Setup Model and Fine-tuning
Loading a pretrained LLM
我们花了很多时间准备用于指令微调的数据集,这是监督微调过程中的一个关键方面 。许多其他方面与预训练相同,使我们能够重用早期章节中的大量代码。
在开始指令微调之前,我们必须首先加载一个我们想要微调的预训练GPT模型(见 图7.15),这是我们之前进行过的过程。
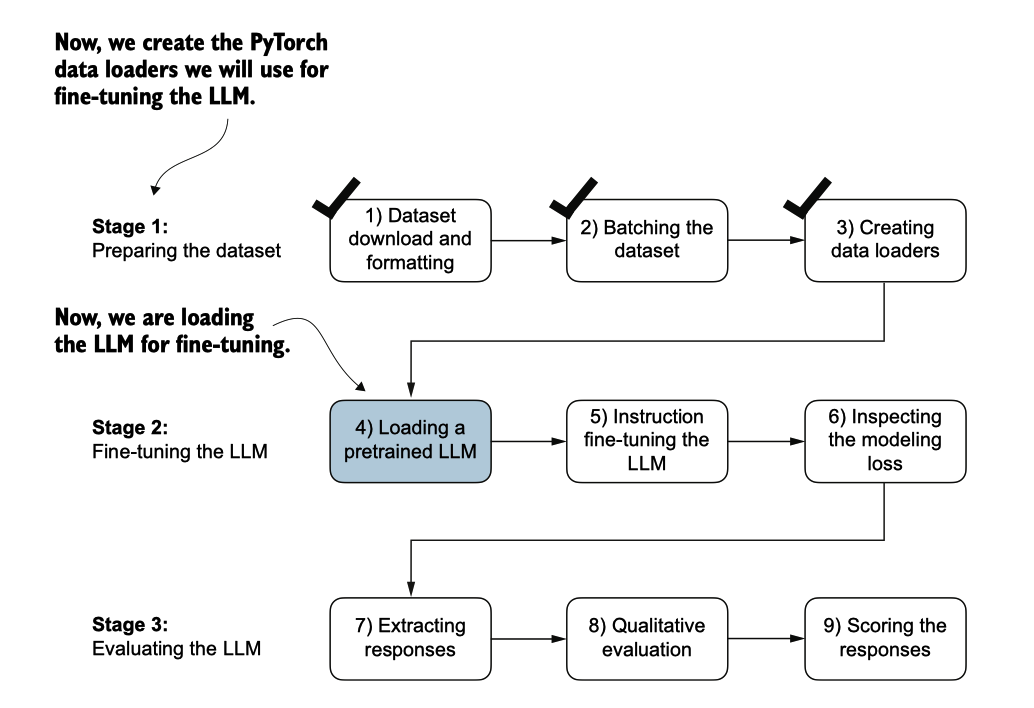
图7.15 三阶段的指令微调大型语言模型(LLM)流程。
通过指令微调获得令人满意的结果。具体来说,较小的模型缺乏学习和保留高质量指 令遵循任务所需的复杂模式和细微行为的必要能力。
加载我们预训练的模型需要与我们预训练数据和为了分类进行微调时相同的代码,只是我们现在指定“gpt2-medium (355M)”而不是“gpt2-sm all (124M)”。
from gpt_download import download_and_load_gpt2
from previous_chapters import GPTModel, load_weights_into_gpt
BASE_CONFIG = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"drop_rate": 0.0, # Dropout rate
"qkv_bias": True # Query-key-value bias
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
CHOOSE_MODEL = "gpt2-medium (355M)"
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
settings, params = download_and_load_gpt2(
model_size=model_size,
models_dir="gpt2"
)
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval();
## output
checkpoint: 100%|██████████| 77.0/77.0 [00:00<00:00, 156kiB/s]
encoder.json: 100%|██████████| 1.04M/1.04M [00:02<00:00, 467kiB/s]
hparams.json: 100%|██████████| 91.0/91.0 [00:00<00:00, 198kiB/s]
model.ckpt.data-00000-of-00001: 100%|██████████| 1.42G/1.42G[05:50<00:00, 4.05MiB/s]
model.ckpt.index: 100%|██████████| 10.4k/10.4k [00:00<00:00, 18.1MiB/s]
model.ckpt.meta: 100%|██████████| 927k/927k [00:02<00:00, 454kiB/s]
vocab.bpe: 100%|██████████| 456k/456k [00:01<00:00, 283kiB/s]
现在,让我们花一点时间评估预训练的LLM在验证任务之一上的表现,通过将其输出 与预期响应进行比较。这将为我们提供一个基线,了解模型在未经微调的情况下,在 指令跟随任务上的表现如何,并帮助我们在后续评估微调的效果。我们将使用验证集 中的第一个示例进行此次评估.
orch.manual_seed(123)
input_text = format_input(val_data[0])
print(input_text)
## output
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the meal every day.'
接下来,我们使用在预训练模型时使用的相同生成函数来生成模型的响应
from previous_chapters import (
generate,
text_to_token_ids,
token_ids_to_text
)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer),
max_new_tokens=35,
context_size=BASE_CONFIG["context_length"],
eos_id=50256,
)
generated_text = token_ids_to_text(token_ids, tokenizer)
## output
The chef cooks the meal every day.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the
generate函数返回组合的输入和输出文本。这种行为之前是便利的,因为预训练的LLM主 要被设计为文本补全模型,在这些模型中,输入和输出被连接在一起以创建连贯且易读的文本。然而,在评估模型在特定任务上的表现时,我们通常希望专注于模型生成的响应。
为了隔离模型的响应文本,我们需要从生成文本的开始减去输入指令的长度
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
print(response_text)
## output
The chef cooks the meal every day.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the
这段代码从生成的文本的开头移除输入文本,只留下模型生成的响应。
该输出表明,预训练模型尚未能够正确遵循给定的指令。虽然它确实创建了一个响应 部分,但它只是重复了原始输入句子和部分指令,未能如请求所示地将主动语态句子 转换为被动语态。
因此,让我们现在实施微调过程,以提高模型理解和适当地回应此类请求的能力。
Fine-tuning the LLM on instruction data
是时候对LLM进行微调以便执行指令(图7.16)。
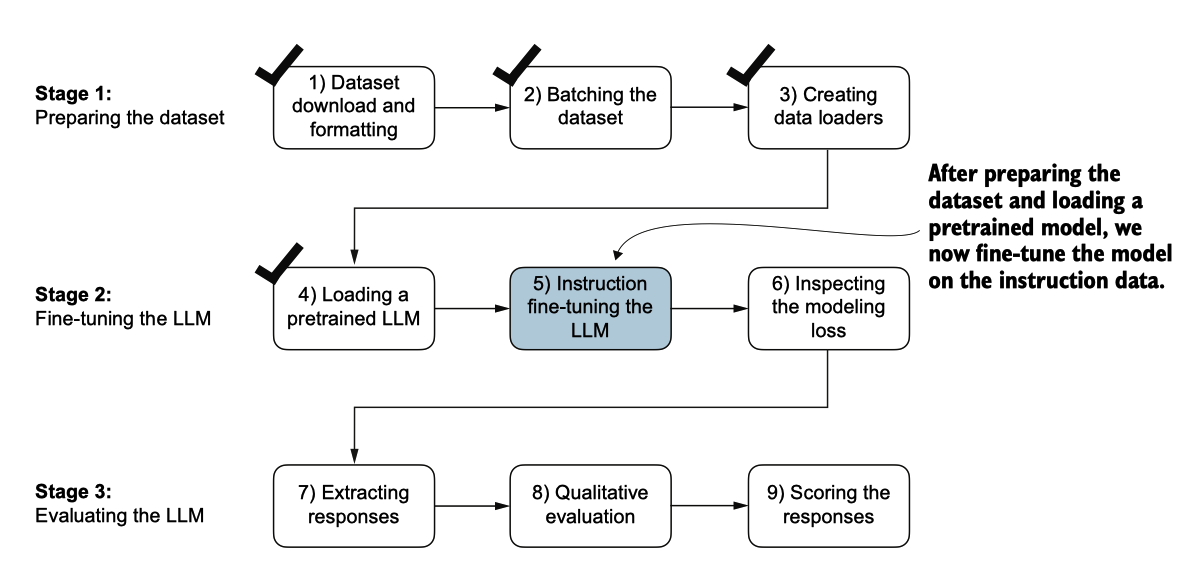
图7.16 对LLM进行指令微调的三阶段过程。在第5步中,我们在之前加载的预训练模型上,在我们早先准备的指令 数据集上进行训练。
我们将采用上述加载的预训练模型,并使用本章早些时候准备的指令数据集进一步训练它。当我们在开头实现指令数据集处理时,所有的繁重工作已经完成。
对于微调过程本身,我们可以重用之前实现的损失计算和训练函数:
from previous_chapters import (
calc_loss_loader,
train_model_simple
)
在我们开始训练之前,让我们计算训练集和验证集的初始损失
model.to(device)
torch.manual_seed(123)
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
## output
Training loss: 3.8259087562561036
Validation loss: 3.761933708190918
准备好模型和数据加载器后,我们现在可以开始训练模型。下面的代码设置了训练过程,包括初始化优化器、设置轮次数量以及定义评估频率和评估生成的 LLM 响应的初始上下文,评估基于我们在之前的第一个验证集指令 (val_data[0]) 。
import time
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.00005, weight_decay=0.1)
num_epochs = 2
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context=format_input(val_data[0]), tokenizer=tokenizer
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")
Ep 1 (Step 000000): Train loss 2.637, Val loss 2.626
Ep 1 (Step 000005): Train loss 1.174, Val loss 1.103
Ep 1 (Step 000010): Train loss 0.872, Val loss 0.944
Ep 1 (Step 000015): Train loss 0.857, Val loss 0.906
Ep 1 (Step 000020): Train loss 0.776, Val loss 0.881
Ep 1 (Step 000025): Train loss 0.754, Val loss 0.859
Ep 1 (Step 000030): Train loss 0.800, Val loss 0.836
Ep 1 (Step 000035): Train loss 0.714, Val loss 0.809
Ep 1 (Step 000040): Train loss 0.672, Val loss 0.806
Ep 1 (Step 000045): Train loss 0.633, Val loss 0.789
Ep 1 (Step 000050): Train loss 0.663, Val loss 0.782
Ep 1 (Step 000055): Train loss 0.760, Val loss 0.763
Ep 1 (Step 000060): Train loss 0.719, Val loss 0.743
Ep 1 (Step 000065): Train loss 0.653, Val loss 0.735
Ep 1 (Step 000070): Train loss 0.536, Val loss 0.732
Ep 1 (Step 000075): Train loss 0.569, Val loss 0.739
Ep 1 (Step 000080): Train loss 0.603, Val loss 0.734
Ep 1 (Step 000085): Train loss 0.518, Val loss 0.717
Ep 1 (Step 000090): Train loss 0.575, Val loss 0.699
Ep 1 (Step 000095): Train loss 0.505, Val loss 0.689
Ep 1 (Step 000100): Train loss 0.507, Val loss 0.683
Ep 1 (Step 000105): Train loss 0.570, Val loss 0.676
Ep 1 (Step 000110): Train loss 0.564, Val loss 0.671
Ep 1 (Step 000115): Train loss 0.522, Val loss 0.666
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is prepared every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive:
Ep 2 (Step 000120): Train loss 0.439, Val loss 0.671
Ep 2 (Step 000125): Train loss 0.454, Val loss 0.685
Ep 2 (Step 000130): Train loss 0.448, Val loss 0.681
Ep 2 (Step 000135): Train loss 0.406, Val loss 0.678
Ep 2 (Step 000140): Train loss 0.412, Val loss 0.678
Ep 2 (Step 000145): Train loss 0.372, Val loss 0.680
Ep 2 (Step 000150): Train loss 0.381, Val loss 0.674
Ep 2 (Step 000155): Train loss 0.419, Val loss 0.672
Ep 2 (Step 000160): Train loss 0.417, Val loss 0.680
Ep 2 (Step 000165): Train loss 0.383, Val loss 0.683
Ep 2 (Step 000170): Train loss 0.328, Val loss 0.679
Ep 2 (Step 000175): Train loss 0.334, Val loss 0.668
Ep 2 (Step 000180): Train loss 0.391, Val loss 0.656
Ep 2 (Step 000185): Train loss 0.418, Val loss 0.657
Ep 2 (Step 000190): Train loss 0.341, Val loss 0.648
Ep 2 (Step 000195): Train loss 0.330, Val loss 0.633
Ep 2 (Step 000200): Train loss 0.313, Val loss 0.631
Ep 2 (Step 000205): Train loss 0.354, Val loss 0.628
Ep 2 (Step 000210): Train loss 0.365, Val loss 0.629
Ep 2 (Step 000215): Train loss 0.394, Val loss 0.634
Ep 2 (Step 000220): Train loss 0.301, Val loss 0.647
Ep 2 (Step 000225): Train loss 0.347, Val loss 0.661
Ep 2 (Step 000230): Train loss 0.297, Val loss 0.659
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is cooked every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What is the capital of the United Kingdom
Training completed in 0.93 minutes.
训练输出表明模型正在有效学习,从两个时期中持续降低的训练和验证损失值可以看 出这一点。这个结果表明模型正在逐渐提高理解和遵循提供的指令的能力。(由于模 型在这两个时期内表现出了有效的学习,延长训练到第三个或更多时期并不是必要的 ,甚至可能适得其反,因为这可能导致过拟合增加。)
此外,在每个时期结束时生成的响应使我们能够检查模型在验证集示例中正确执行 给定任务的进展。在这种情况下,模型成功地将主动句"The chef cooks the meal every day."转换 为其被动语态对应句:"The meal is cooked every day by the chef."
我们稍后将更详细地回顾和评估模型的响应质量。现在,让我们检查训练和验证损 失曲线,以更深入地了解模型的学习过程。为此,我们使用与预训练时相同的plot_losses 函数:
from previous_chapters import plot_losses
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
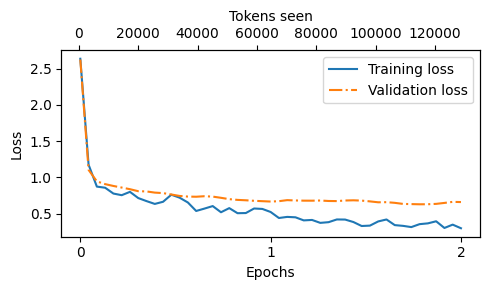
图 7.17 两个周期内训练和验证损失的趋势。实线代表训练损失 ,在稳定之前显示出急剧下降,而虚线代表验证损失,遵循类 似的模式。
从图7.17所示的损失图中,我们可以看到模型在训练集和验证集上的表现随着训练过 程的推进显著改善。初始阶段损失的快速下降表明模型迅速从数据中学习到有意义的 模式和表示。然后,当训练进入第二个时代时,损失继续减少,但速度较慢。
虽然图7.17中的损失图表明模型正在有效训练,但最关键的方面是其在响应质量和准 确性方面的表现。因此,我们接下来提取响应并将其存储在一种可以评估和量化响应 质量的格式中。
Extracting and saving responses
在针对指令数据集的训练部分微调了LLM之后,我们现在准备好在保留的测试集上评 估其性能。首先,我们提取测试数据集中每个输入生成的模型响应,并将其收集进行 人工分析,然后我们评估LLM以量化响应的质量,如图7.18所示。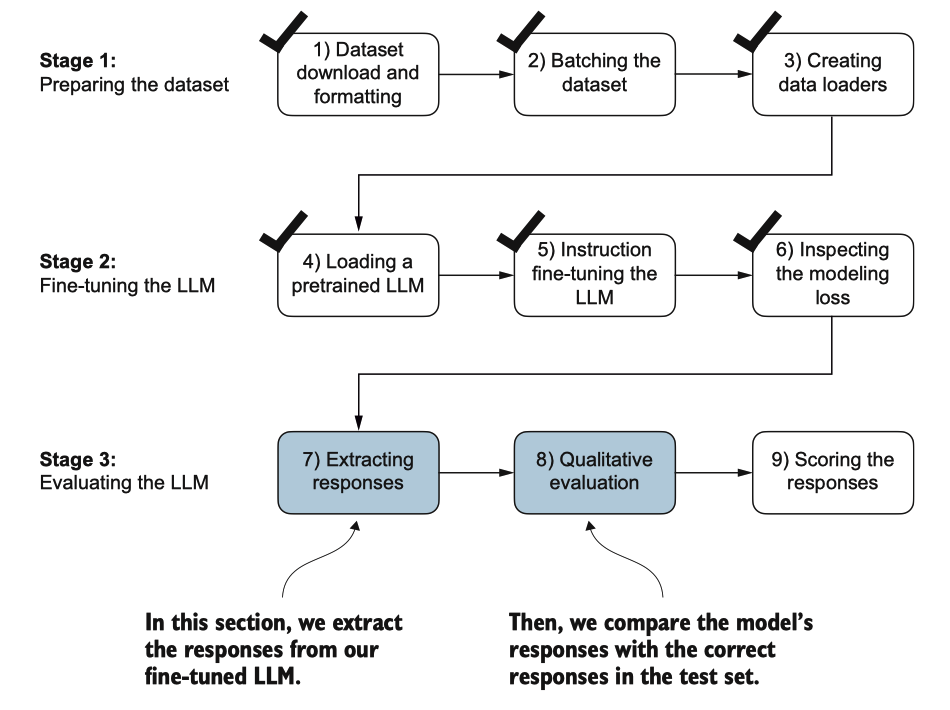
图7.18 LLM的指导微调的三阶段过程。在第三阶段的前两步中,我们提取并收集在保留的 测试数据集上的模型响应以进行进一步分析,然后评估模型以量化指导微调后的LLM的性 能。
为了完成响应指令步骤,我们使用generate函数。然后,我们打印模型响应,以及前三个测试集条目的预期答案,将它们并排展示以便比较:
torch.manual_seed(123)
for entry in test_data[:3]:
input_text = format_input(entry)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
print(input_text)
print(f"\nCorrect response:\n>> {entry['output']}")
print(f"\nModel response:\n>> {response_text.strip()}")
print("-------------------------------------")
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence using a simile.
### Input:
The car is very fast.
Correct response:
>> The car is as fast as lightning.
Model response:
>> The car is as fast as a bullet.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What type of cloud is typically associated with thunderstorms?
Correct response:
>> The type of cloud typically associated with thunderstorms is cumulonimbus.
Model response:
>> The type of cloud associated with thunderstorms is a cumulus cloud.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name the author of 'Pride and Prejudice'.
Correct response:
>> Jane Austen.
Model response:
>> The author of 'Pride and Prejudice' is Jane Austen.
-------------------------------------
根据测试集说明、给定的回答和模型的回答,我们可以看到该模型的表现相对较好。 第一和最后一条指令的答案显然是正确的,而第二个答案虽然接近但并不完全准确。
最重要的是,模型评估并不像完成微调那样简单,我们只需计算正确的垃圾邮件/ 非垃圾邮件类别标签的百分比来获得分类的准确性。实际上,像聊天机器人这样的指 令微调大型语言模型(LLM)的评估通过多种方法进行:
- 短答案和多项选择基准,例如《测量大规模多任务语言理解》(MMLU;https://arxiv.org/abs/2009.03300),用于测试模型的通用知识。
- 与其他大型语言模型(LLMs)的人工偏好比较,例如 LMSYS 聊天机器人竞技场(https://arena.lmsys.org)。
- 自动化对话基准,其中使用其他大型语言模型如 GPT-4 来评估回复,例如 AlpacaEval(https://tatsu-lab.github.io/alpaca_eval/)。
在实际操作中,考虑所有三种评估方法是有用的:选择题回答、人类评估和测量对话 性能的自动化指标。然而,由于我们主要关注评估对话性能,而不仅仅是回答选择题 的能力,人类评估和自动化指标可能更为相关。
[!NOTE] Conversational performance
LLM的对话表现(Conversational performance)指的是它们通过理解上下文、细微差别和意图与人类进行类人交流的能力。它包括提供相关和连贯的回复、保持一致性以及适应不同主题和交互风格等技能。
人工评估虽然提供了宝贵的见解,但在处理大量回应时可能相对繁琐且耗时。例如, 阅读并给所有1,100个回应评分将需要相当大的努力。
因此,考虑到手头任务的规模,我们将实施一种类似于自动对话基准的方法,该方法涉及使用另一个LLM自动评估响应。此方法将使我们能够有效地评估生成响应的质量,而无需大量人力介入,从而节省时间和资源,同时仍能获得有意义的绩效指标。
让我们采用一种受到AlpacaEval启发的方法,使用另一个LLM来评估我们微调模型的响应。然而,我们不依赖于公开可用的基准数据集,而是使用我们自己的自定义测试集。这种自定义使我们能够在预期用例的上下文中,更加针对性和相关性地评估模型的性能,这些用例在我们的指令数据集中得以体现。
为了准备本次评估过程的响应,我们将生成的模型响应附加到 test_set 字典中,并 将更新后的数据保存为 "instruction-data-with-response.json" 文件以便记录。 此外,通过保存此文件,我们可以在后续的 Python 会话中方便地加载和分析响应,如有需要。
以下代码清单以与之前相同的方式使用 generate 方法;然而,我们现在迭代整个 tes tset。此外,我们不再打印模型响应,而是将其添加到 testset 字典中。
from tqdm import tqdm
for i, entry in tqdm(enumerate(test_data), total=len(test_data)):
input_text = format_input(entry)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = generated_text[len(input_text):].replace("### Response:", "").strip()
test_data[i]["model_response"] = response_text
with open("instruction-data-with-response.json", "w") as file:
json.dump(test_data, file, indent=4) # "indent" for pretty-printing
print(test_data[0])
## output
{'instruction': 'Rewrite the sentence using a simile.', 'input': 'The car is very fast.', 'output': 'The car is as fast as lightning.', 'model_response': 'The car is as fast as a bullet.'}
让我们通过检查测试集(test_set)字典中的一个条目来验证响应是否已正确添加.
最后,我们将模型保存为 gpt2-medium355M-sft.pth 文件,以便在未来的项目中重用。
import re
file_name = f"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft.pth"
torch.save(model.state_dict(), file_name)
print(f"Model saved as {file_name}")
# Load model via
# model.load_state_dict(torch.load("gpt2-medium355M-sft.pth"))
## output
Model saved as gpt2-medium355M-sft.pth