别着急,坐和放宽
Fine-tuning the model on supervised data
我们必须定义并使用训练函数来微调预训练的 LLM,并提高其垃圾邮件分类准确性。 训练循环如图 6.15 所示,与我们用于预训练的整体训练循环相同;唯一的区别是我们 计算分类准确性,而不是生成样本文本来评估模型。
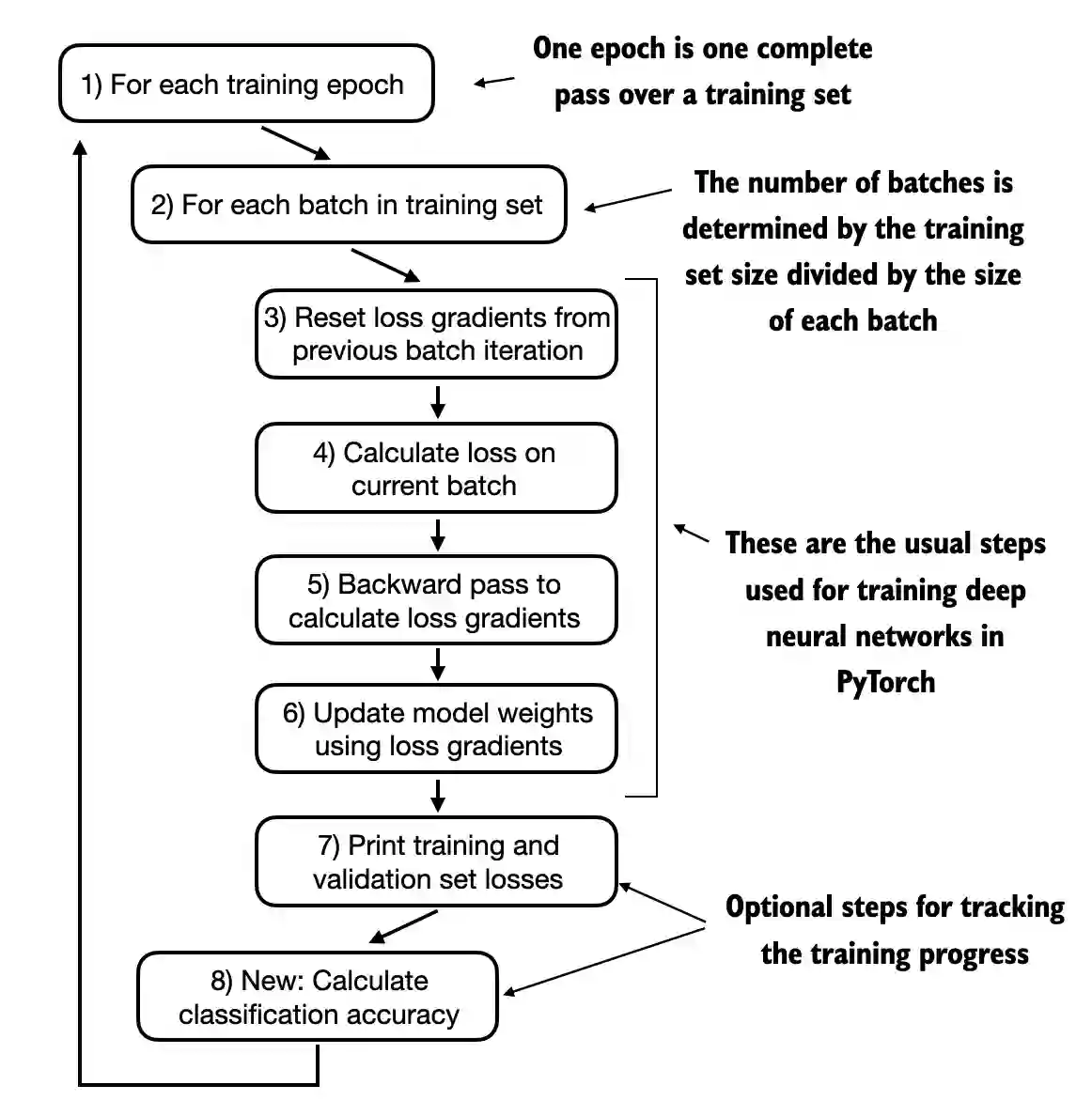
图 6.15 训练深度神经网络的典型训练循环在 PyTorch 中由几个步骤组成,遍 历训练集中的批次,进行多个周期。
训练函数实现了图6.15中显示的概念,也与用于模型预训练的trainmodelsimple函数密切对应。唯一的两个区别是我们现在跟踪看到的训练样本数量(examples_seen), 而不是标记的数量,并且我们在每个训练周期后计算准确率,而不是打印样本文本。
CodeBlock Loading...
接下来,我们初始化优化器,设置训练的轮数,并使用 trainclassifiersimple 函数开 始训练。在 M3 MacBook Air 笔记本电脑上,训练大约需要 6 分钟,而在 V100 或 A10 0 GPU 上则少于半分钟:
import time
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5,weight_decay=0.1)
num_epochs = 5
train_losses, val_losses, train_accs, val_accs, examples_seen = \
train_classifier_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=50,eval_iter=5)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")
## output

Output
我们然后使用 Matplotlib 绘制训练集和验证集的损失函数。
CodeBlock Loading...
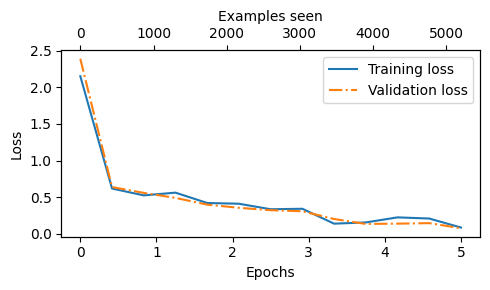
图6.16 模型在五个训练周期中的训练损失和验证损失。
根据图 6.16 中明显的急剧下降趋势,我们可以看出模型正在很好地从训练数据中学习,并且几乎没有过拟合的迹象;也就是说,训练集和验证集损失之间没有明显的差距。
[!NOTE] 迭代次数的选择
早些时候,当我们开始训练时,我们将训练周期的数量设定为五个。训练周期的数量取决于数据集和任务的难度,并没有通用的解决方案或推荐,尽管五个周期通常是一个不错的起点。如果模型在前几个周期后出现过拟合,如损失图所示(见图6.16 ),您可能需要减少周期的数量。相反,如果趋势线表明验证损失在进一步训练中可能改善,则应增加训练周期的数量。在这个具体案例中,五个周期是一个合理的数字,因为没有早期过拟合的迹象,且验证损失接近0。
CodeBlock Loading...
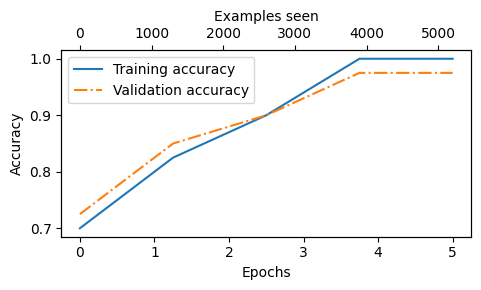
图 6.17 训练准确率(实线)和验证准确率(虚线)在早期轮次中显著提 高,然后趋于平稳,几乎达到完美的准确率分数 1.0。
在使用 trainclassifiersimple 函数时,这意味着我们的训练和验证性能的估计仅基于 五个批次,以提高训练的效率。
现在我们必须通过运行以下代码来计算整个数据集的训练、验证和测试集的性能指 标,这次不定义 eval_iter 的值:
CodeBlock Loading...
训练集和测试集的表现几乎完全相同。训练集和测试集准确率之间的微小差异表明对训练数据的过拟合程度很小。通常,验证集的准确率要高于测试集的准确率,因为模型开发往往涉及调整超参数以在验证集上表现良好,这可能无法有效地推广到测试集 。这种情况很常见,但可以通过调整模型的设置,如增加 dropout 率 (droprate) 或优 化器配置中的 weightdecay 参数,来尽量缩小这个差距。
Using the LLM as a spam classifier
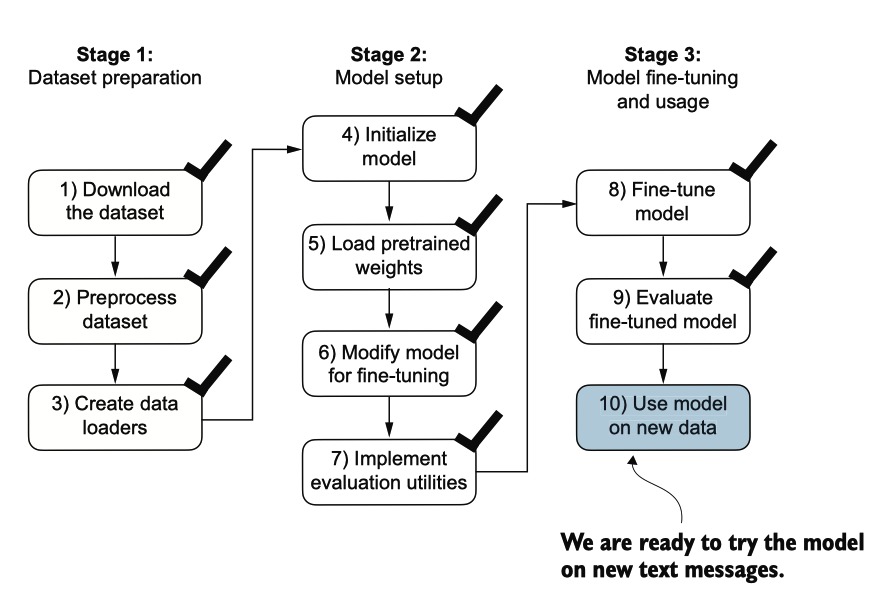
图6.18 分类微调我们的大型语言模型的三阶段过程。
经过微调和评估模型后,我们现在准备分类垃圾消息(见图6.18)。让我们使用我们 微调的基于GPT的垃圾分类模型。
以下 classify_review 函数遵循与我们之前在SpamDataset中使用的类似的数据预处理步骤。然后,在将文本处理为令牌ID后,该函数使用模型预测一个整数类别标签,然后返回相应的类别名称。
CodeBlock Loading...
让我们在一个示例文本上尝试这个 classify_review 函数:
CodeBlock Loading...
CodeBlock Loading...
最后,我们保存模型, 以便将来如果想要重新使用模型时,无需再次训练它。我们可以使用torch.save方法.保存后,也可以加载模型
CodeBlock Loading...
Summary
- 对LLM进行fine-tuning有不同的策略,包括classification fine-tuning和instruction fine-tuning。
- Classification fine-tuning涉及通过一个小型分类层替换LLM的输出层。
- 在将文本消息分类为"垃圾邮件"或"非垃圾邮件"的情况下,新的分类层仅包含两个输出节点。此前,我们使用的输出节点数量等于词汇表中唯一token的数量(即50,256个)。
- 与预训练时预测文本中的下一个token不同,classification fine-tuning训练模型输出正确的类别标签——例如"垃圾邮件"或"非垃圾邮件"。
- Fine-tuning的模型输入是转换为token ID的文本,这与预训练类似。
- 在对LLM进行fine-tuning之前,我们需要先加载预训练好的基础模型。
- 评估分类模型涉及计算分类准确率(正确预测的比例或百分比)。
- Fine-tuning分类模型使用与预训练LLM时相同的交叉熵损失函数。