Fine-tuning for classification 1. Prepare dataset and Create data loader
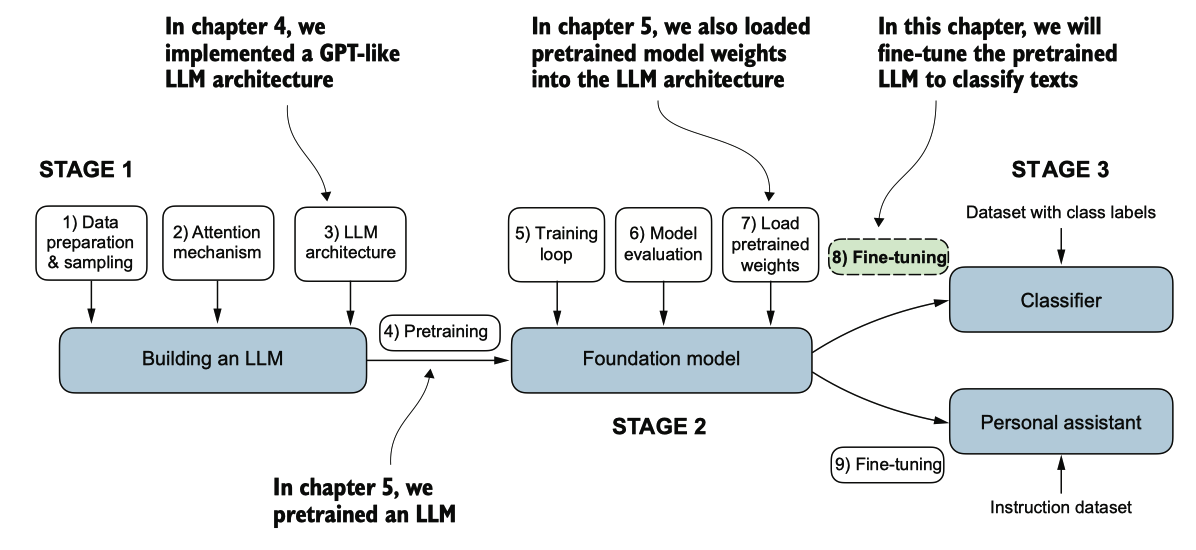
图6.1 LLM编码的三个主要阶段。本章重点关注阶段3(步骤8):将预训练的LLM作为分类器进行微调。
微调语言模型的最常见方法是 instruction fine-tuning (指令微调) 和 classification fine-tuning(分类微调)。指令微调涉及在一组任务上训练语言模型,使用特定指令提高其理解和执行自然语言提示中描述的任务的能力,如图 6.2 所示。
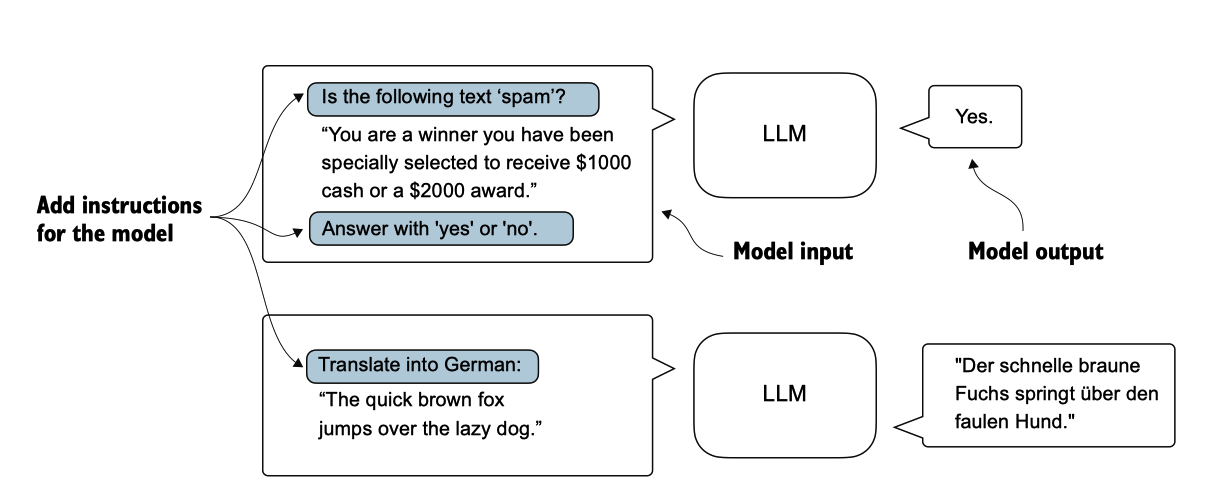
图 6.2 两种不同的指令微调场景。在顶部,模型的任务是判断给定文本是否为垃圾邮件。在底部,模型收到一条 如何将英语句子翻译成德语的指令。
经过微调的分类模型仅限于预测在训练过程中遇到的类别。例如,它 可以判断某个内容是“垃圾邮件”还是“非垃圾邮件”,如图 6.3 所示,但它无法对 输入文本做出其他任何判断。
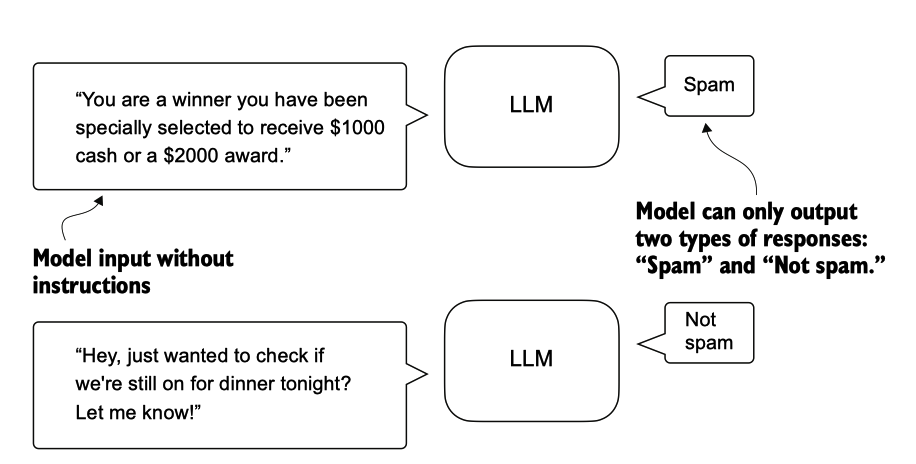
图 6.3 使用 LLM 的文本分类场景。为了垃圾邮件分类而微调的模型不需要在输入旁边 提供进一步的指示。与经过指示微调的模型相比,它只能以“垃圾邮件”或“非垃圾 邮件”作出回应。
与图6.3中所示的分类微调模型相比,指令微调模型通常可以承担更广泛的任务。我们 可以将分类微调模型视为高度专业化的,而通常来说,开发一个专门模型比开发一个 在各种任务中表现良好的通用模型更容易。
[!NOTE] 选择正确的方法
指令微调提升了模型理解和生成基于特定用户指令的响应的能力。指令微调最适合 需要根据复杂用户指令处理多种任务的模型,从而提高灵活性和互动质量。分类微调非常适合需要将数据精确分类到预定义类别中的项目,例如情感分析或垃圾邮件检测。
虽然指令微调更具灵活性,但它需要更大的数据集和更多的计算资源来开发能够在 各种任务中熟练的模型。相比之下,分类微调所需的数据和计算能力较少,但其使 用仅限于模型训练过的特定类别。
Preparing the dataset
我们将修改并进行分类微调我们之前实现并预训练的GPT模型。我们首先下载并准备 数据集,如图6.4所示。为了提供一个直观且有用的分类微调示例,我们将处理一个包 含垃圾短信和非垃圾短信的文本消息数据集。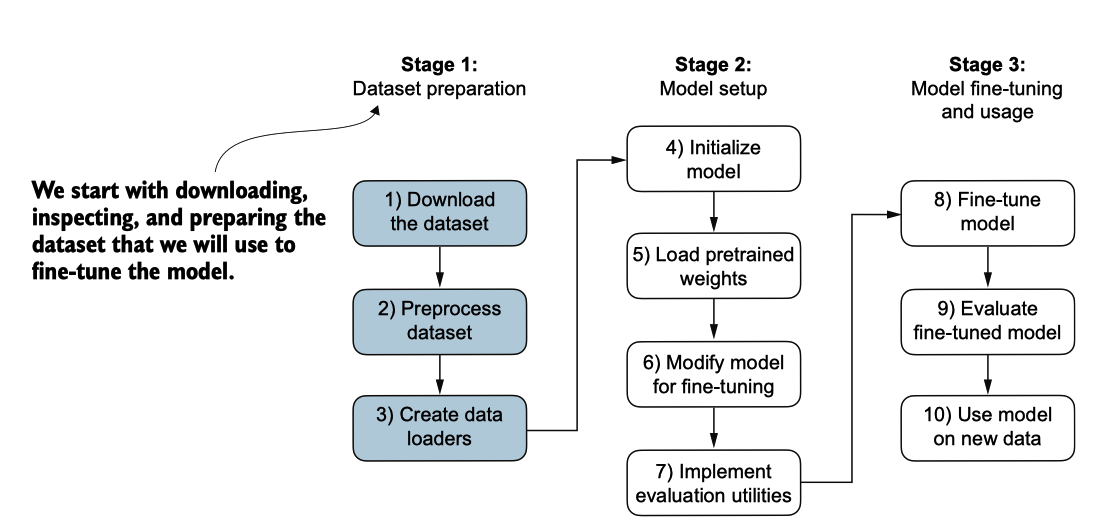
图6.4 用于分类微调LLM的三级过程。阶段1涉及数据集准备。阶段2专注于模型设置。阶段3涵盖微调 和评估模型。
import urllib.request
import zipfile
import os
from pathlib import Path
url = "https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip"
zip_path = "sms_spam_collection.zip"
extracted_path = "sms_spam_collection"
data_file_path = Path(extracted_path) / "SMSSpamCollection.tsv"
def download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path):
if data_file_path.exists():
print(f"{data_file_path} already exists. Skipping download and extraction.")
return
# Downloading the file
with urllib.request.urlopen(url) as response:
with open(zip_path, "wb") as out_file:
out_file.write(response.read())
# Unzipping the file
with zipfile.ZipFile(zip_path, "r") as zip_ref:
zip_ref.extractall(extracted_path)
# Add .tsv file extension
original_file_path = Path(extracted_path) / "SMSSpamCollection"
os.rename(original_file_path, data_file_path)
print(f"File downloaded and saved as {data_file_path}")
download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)
在执行之前的代码后,数据集被保存为一个制表符分隔的文本文件 SMSSpamCollectio n.tsv,位于 smsspamcollection 文件夹中。我们可以将其加载到 pandas DataFrame 中 ,如下所示:
import pandas as pd
df = pd.read_csv(data_file_path, sep="\t", header=None, names=["Label", "Text"])
df

output
让我们看查下分类标签的分布
print(df["Label"].value_counts())
## output
Label
ham 4825
spam 747
Name: count, dtype: int64
为了简单起见,并且因为我们更喜欢一个小的数据集(这将有助于更快地微调LLM) ,我们选择对数据集进行欠采样,以包括每个类别的747个实例。
def create_balanced_dataset(df):
# Count the instances of "spam"
num_spam = df[df["Label"] == "spam"].shape[0]
# Randomly sample "ham" instances to match the number of "spam" instances
ham_subset = df[df["Label"] == "ham"].sample(num_spam, random_state=123)
# Combine ham "subset" with "spam"
balanced_df = pd.concat([ham_subset, df[df["Label"] == "spam"]])
return balanced_df
balanced_df = create_balanced_dataset(df)
print(balanced_df["Label"].value_counts())
## output
Label
ham 747
spam 747
Name: count, dtype: int64
接下来,我们将“字符串”类别标签“ham”和“spam”分别转换为整数类别标签0和 1,这个过程类似于将文本转换为令牌ID。然而,我们处理的仅仅是两个令牌ID:0和1, 而不是使用包含超过50,000个单词的GPT词汇表。
接下来,我们创建一个 random_split 函数,将数据集分成三部分:70% 用于训练, 10% 用于验证,20% 用于测试。(这些比例在机器学习中很常见,用于训练、调整和 评估模型。)
balanced_df["Label"] = balanced_df["Label"].map({"ham": 0, "spam": 1})
def random_split(df, train_frac, validation_frac):
# Shuffle the entire DataFrame
df = df.sample(frac=1, random_state=123).reset_index(drop=True)
# Calculate split indices
train_end = int(len(df) * train_frac)
validation_end = train_end + int(len(df) * validation_frac)
# Split the DataFrame
train_df = df[:train_end]
validation_df = df[train_end:validation_end]
test_df = df[validation_end:]
return train_df, validation_df, test_df
train_df, validation_df, test_df = random_split(balanced_df, 0.7, 0.1)
# Test size is implied to be 0.2 as the remainder
train_df.to_csv("train.csv", index=None)
validation_df.to_csv("validation.csv", index=None)
test_df.to_csv("test.csv", index=None)
Creating Data Loaders
我们将开发与我们在处理文本数据时实现的概念上类似的 PyTorch 数据加载器。
之前 ,我们利用滑动窗口技术生成均匀大小的文本块,然后将它们分组为批次,以便更高效地进行模型训练。每个块作为一个独立的训练实例。
然而,我们现在处理的是一个包含不同长度文本消息的垃圾邮件数据集。为了像处理文本块一样对这些消息进行批 处理,我们有两个主要选项:
- 将所有消息截断至数据集或批次中最短消息的长度。
- 将所有消息填充至数据集或批次中最长消息的长度。
第一个选项在计算上更便宜,但如果较短的消息远小于平均或最长消息,则可能会导 致显著的信息丢失, 潜在地降低模型性能。因此,我们选择第二个选项,这保留了所有消息的全部内容。
为了实现批处理,将所有消息填充到数据集中最长消息的长度,我们为所有较短的 消息添加填充标记。为此,我们使用 "<|endoftext|>" 作为填充标记。
然而,我们并不是将字符串 "<|endoftext|>" 直接附加到每条文本消息上,而是可以 将与 "<|endoftext|>" 对应的令牌 ID 添加到编码后的文本消息中,如图 6.6 所示。
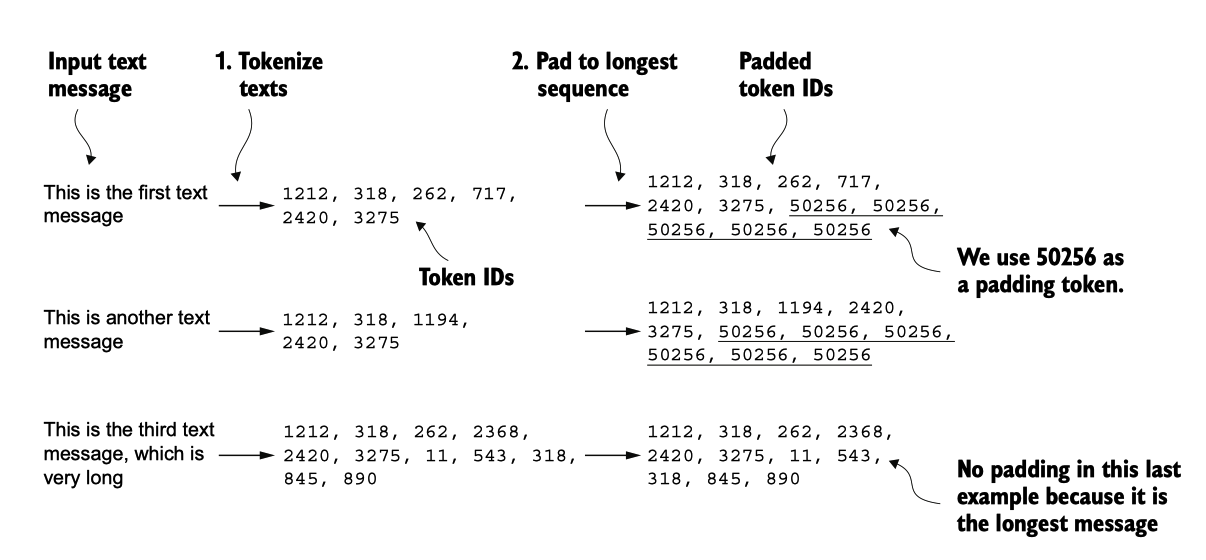
图 6.6 输入文本准备过程。首先,每个输入文本消息被转换为一系列令牌ID。然后,为了确保序列长度统一,较短 的序列用填充令牌(在这种情况下,令牌ID 50256)进行填充,以匹配最长序列的长度。
我们首先需要实现一个 PyTorch 数据集,该数据集指定了数据在实例化数据加载器之前是如何加载和处理的。
为此,我们定义了 SpamDataset 类,该类实现了图 6.6 中的概念。这个 SpamDataset 类处理几个关键任务:它识别训练数据集中最长的序列,编码文本消息,并确保所有其他序列都用 padding token 填充,以匹配最长序列的长度.
import torch
from torch.utils.data import Dataset
class SpamDataset(Dataset):
def __init__(self, csv_file, tokenizer, max_length=None, pad_token_id=50256):
self.data = pd.read_csv(csv_file)
# Pre-tokenize texts
self.encoded_texts = [
tokenizer.encode(text) for text in self.data["Text"]
]
if max_length is None:
self.max_length = self._longest_encoded_length()
else:
self.max_length = max_length
# Truncate sequences if they are longer than max_length
self.encoded_texts = [
encoded_text[:self.max_length]
for encoded_text in self.encoded_texts
]
# Pad sequences to the longest sequence
self.encoded_texts = [
encoded_text + [pad_token_id] * (self.max_length - len(encoded_text))
for encoded_text in self.encoded_texts
]
def __getitem__(self, index):
encoded = self.encoded_texts[index]
label = self.data.iloc[index]["Label"]
return (
torch.tensor(encoded, dtype=torch.long),
torch.tensor(label, dtype=torch.long)
)
def __len__(self):
return len(self.data)
def _longest_encoded_length(self):
max_length = 0
for encoded_text in self.encoded_texts:
encoded_length = len(encoded_text)
if encoded_length > max_length:
max_length = encoded_length
return max_length
# Note: A more pythonic version to implement this method
# is the following, which is also used in the next chapter:
# return max(len(encoded_text) for encoded_text in self.encoded_texts)
SpamDataset 类从我们之前创建的 CSV 文件中加载数据,使用 tiktoken 的 GPT-2 分词 器对文本进行分词,并允许我们将序列 pad 或 truncate 为由最长序列或预定义的最大 长度确定的均匀长度。这确保了每个输入张量具有相同的大小,这是我们接下来实现的训练数据加载器中创建批次所必需的。
最长的序列长度存储在数据集的 max_length 属性中。如果您想查看最长序列中的标记 数量,可以使用以下代码:
train_dataset = SpamDataset(
csv_file="train.csv",
max_length=None,
tokenizer=tokenizer
)
print(train_dataset.max_length)
## output
120
该代码输出120,显示最长的序列不超过120个标记,这是文本消息的常见长度。考虑 到其上下文长度限制,该模型可以处理最多1,024个标记的序列。如果您的数据集包含 更长的文本,您可以在前面的代码中创建训练数据集时传递max_length=1024,以确保 数据不会超过模型支持的输入(上下文)长度。
接下来,我们对验证集和测试集进行填充,以匹配最长训练序列的长度。重要的是 ,任何超过最长训练示例长度的验证和测试集样本都将通过我们之前定义的SpamDataset代码中的encodedtext[:self.maxlength]进行截断。这个截断是可选的;您可以将ma x_length=设置为None,前提是这些集中没有超过1,024个标记的序列
val_dataset = SpamDataset(
csv_file="validation.csv",
max_length=train_dataset.max_length,
tokenizer=tokenizer
)
test_dataset = SpamDataset(
csv_file="test.csv",
max_length=train_dataset.max_length,
tokenizer=tokenizer
)
使用数据集作为输入,我们可以像处理文本数据时一样实例化数据加载器。然而,在这种情况下,目标表示的是类别标签,而不是文本中的下一个标记。
例如,如果我们选择批次大小为8,则每个批次将包含八个长度为120的训练示例及每个示例的相应类别标签,如图6.7所示。
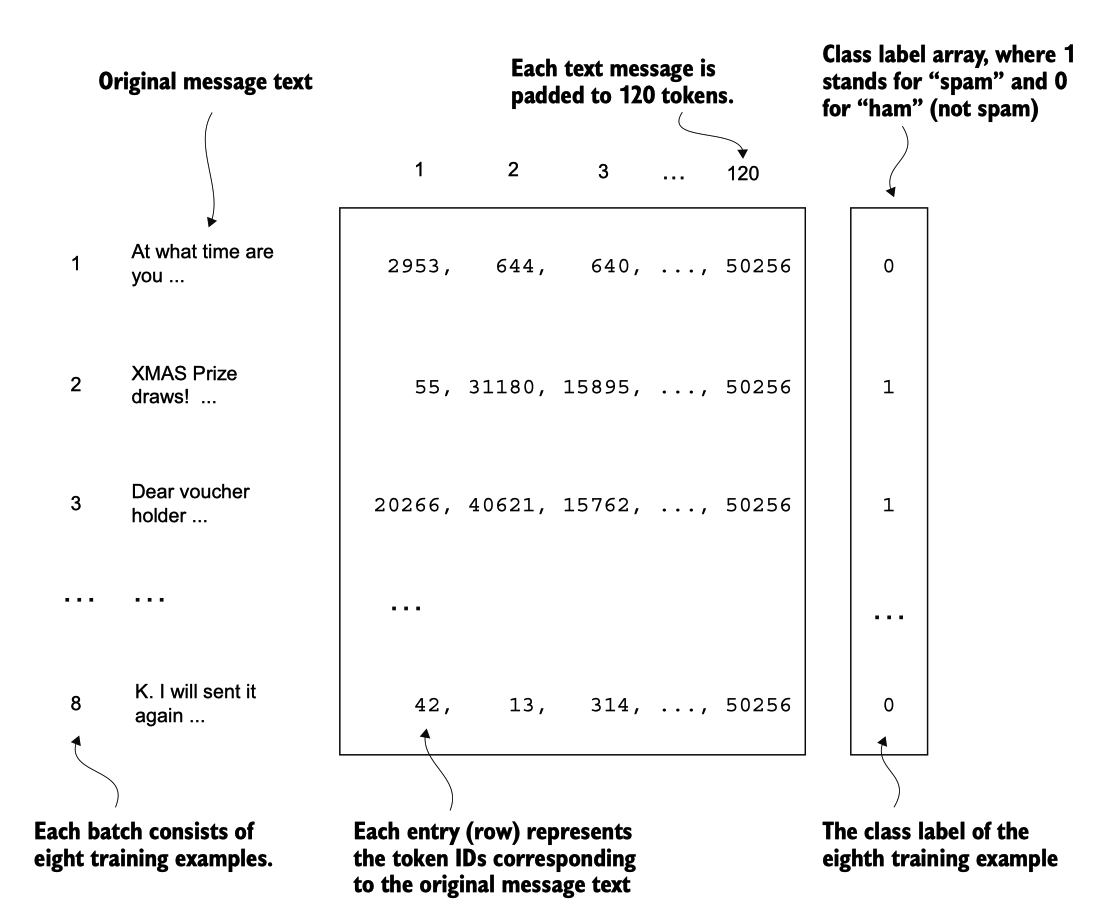
图 6.7 一个单独的训练批次,由八个文本消息组成,这些文本消息表示为标记IDs。每个文本消息包含120个标记 IDs。一个类别标签数组存储与文本消息对应的八个类别标签,这些标签可以是 0(“非垃圾邮件”)或 1(“垃圾邮件”)。
以下列表中的代码创建了训练、验证和测试集数据加载器,这些加载器以批次大小为 8加载文本消息和标签。
rom torch.utils.data import DataLoader
num_workers = 0
batch_size = 8
torch.manual_seed(123)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
drop_last=True,
)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=False,
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=False,
)
为了确保数据加载器正常工作,并且确实返回的是期望大小的批次,我们迭代训练加载器,然后打印最后一个批次的张量维度:
print("Train loader:")
for input_batch, target_batch in train_loader:
pass
print("Input batch dimensions:", input_batch.shape)
print("Label batch dimensions", target_batch.shape)
## output
Train loader:
Input batch dimensions: torch.Size([8, 120])
Label batch dimensions torch.Size([8])
正如我们所看到的,输入批次由八个训练示例组成,每个示例包含120个标记,正如预期的那样。标签张量存储与这八个训练示例对应的类别标签。
最后,为了了解数据集的大小,让我们打印每个数据集中的总批次数:
print(f"{len(train_loader)} training batches")
print(f"{len(val_loader)} validation batches")
print(f"{len(test_loader)} test batches")
## output
130 training batches
19 validation batches
38 test batches