Pretraining GPT model with unlabeled data 3. Decoding strategies to control randomness
让我们看一下文本生成策略(也称为解码策略),以生成更多原创文本。首先,我们将简要回顾一下之前在 generateandprintsample 中使用的 generatetext_simple 函数 。然后我们将介绍两种技术,temperature scaling 和 top-k sampling,以改善该函数。
接下来,我们将 GPTModel 实例 (model) 插入 generatetextsimple 函数,该函数使用 LLM 一次生成一个令牌:
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer),
max_new_tokens=25,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
## output
Output text:
Every effort moves you know," was one of the axioms he laid down across the Sevres and silver of an exquisitely appointed lun
正如之前所解释的,生成的标记是在每个生成步骤中从词汇表中所有标记中选择具有最大概率得分的标记。这意味着即使我们在相同的起始上下文((Every effort moves you)上多次运行之前的 generatetextsimple 函数,LLM 也始终会生成相同的输出。
Temperature scaling
现在让我们看一下Temperature scaling, 这是一种为下一个令牌生成任务添加概率选择过程的技术。在之前的generatetextsimple函数中,我们始终使用torch.argmax(也称为 greedy decoding)来抽样具有最高概率的令牌作为下一个令牌。为了生成更具多样性的 文本,我们可以将argmax替换为一个从概率分布中抽样的函数(在这里,是LLM在每个令牌生成步骤为每个词汇条目生成的概率分数)。
为了通过一个具体的例子来说明概率采样,我们简要讨论一下使用非常小的词汇量 进行下一个词生成的过程:
vocab = {
"closer": 0,
"every": 1,
"effort": 2,
"forward": 3,
"inches": 4,
"moves": 5,
"pizza": 6,
"toward": 7,
"you": 8,
}
inverse_vocab = {v: k for k, v in vocab.items()}
# Suppose input is "every effort moves you", and the LLM
# returns the following logits for the next token:
next_token_logits = torch.tensor(
[4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79]
)
probas = torch.softmax(next_token_logits, dim=0)
next_token_id = torch.argmax(probas).item()
# The next generated token is then as follows:
print(inverse_vocab[next_token_id])
## output
forward
接下来,假设LLM给定的起始上下文是“every effort moves you”,并生成以下下一个标记的logits.
在generatetextsimple内部,我们通过softmax函数将logits转换为概率,并通过argmax函数获得与生成的token对应的token ID,然后我们可以通过逆词汇表将其映射回文本.
由于最大的logit值以及相应的最大的softmax概率得分位于第四个位置(索引位置3, 因为Python使用0索引),生成的词是“forward”。
要实现一个概率采样过程,我们现在可以在 PyTorch 中用多项式函数替换 argmax.
torch.manual_seed(123)
next_token_id = torch.multinomial(probas, num_samples=1).item()
print(inverse_vocab[next_token_id])
##output
forward
打印输出仍然是“forward”,就像之前一样。发生了什么?
多项式函数根据其概率得 分采样下一个标记。换句话说,“forward”仍然是最可能的标记,且大多数情况下会 被多项式选择,但并非每次。为了说明这一点,让我们实现一个函数,重复此采样1,0 00次:
def print_sampled_tokens(probas):
torch.manual_seed(123) # Manual seed for reproducibility
sample = [torch.multinomial(probas, num_samples=1).item() for i in range(1_000)]
sampled_ids = torch.bincount(torch.tensor(sample))
for i, freq in enumerate(sampled_ids):
print(f"{freq} x {inverse_vocab[i]}")
print_sampled_tokens(probas)
## output
73 x closer
0 x every
0 x effort
582 x forward
2 x inches
0 x moves
0 x pizza
343 x toward
这意味着如果我们在 generateandprint_sample 函数中用多项式函数替换 argmax 函数,LLM 有时会生成诸如every effort moves you toward, every effort moves
you inches, and every effort moves you closer instead of every effort moves you forward。
我们可以通过一个叫做 temperature scaling. 的概念进一步控制分布和选择过程。temperature scaling只是用来描述将 logits 除以一个大于 0 的数字的Fancy表达。
def softmax_with_temperature(logits, temperature):
scaled_logits = logits / temperature
return torch.softmax(scaled_logits, dim=0)
温度大于1会导致更均匀分布的令牌概率,而小于1的温度将导致更自信(更陡峭或更 尖峰)的分布。让我们通过绘制原始概率与使用不同温度值缩放的概率进行说明:
# Temperature values
temperatures = [1, 0.1, 5] # Original, higher confidence, and lower confidence
# Calculate scaled probabilities
scaled_probas = [softmax_with_temperature(next_token_logits, T) for T in temperatures]
x = torch.arange(len(vocab))
bar_width = 0.15
fig, ax = plt.subplots(figsize=(5, 3))
for i, T in enumerate(temperatures):
rects = ax.bar(x + i * bar_width, scaled_probas[i], bar_width, label=f'Temperature = {T}')
ax.set_ylabel('Probability')
ax.set_xticks(x)
ax.set_xticklabels(vocab.keys(), rotation=90)
ax.legend()
plt.tight_layout()
plt.savefig("temperature-plot.pdf")
plt.show()
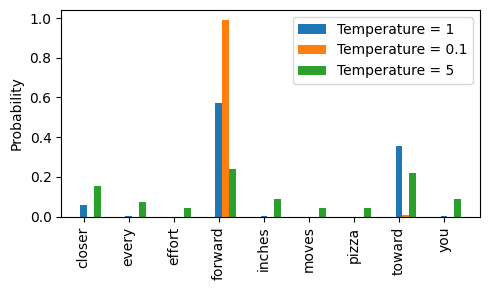
图 5.14 温度为 1 时表示词汇中每个标记的未缩放概率得分。
温度为1时,在将logits传递给softmax函数以计算概率分数之前,先将它们除以1。 换句话说,使用温度为1与不使用任何温度缩放是一样的。在这种情况下,令牌的选择概率等于通过PyTorch中的多项式采样函数得到的原始softmax概率分数。
正如我们在图5.14中所看到的,施加非常小的温度,例如0.1,将导致更尖锐的分布,使得多项式函数的行为几乎100%选择最可能的标记(这里是“forward”), 接近argmax函数的行为。同样,温度为5时会导致更均匀的分布,其他标记被选择的频率更高。这可以为生成的文本增添更多的多样性,但也更容易导致无意义的文本。
Top-k sampling
我们现在实施了一种概率采样方法,并结合温度缩放来增加输出的多样性。我们发现 较高的温度值会导致下一个标记概率更均匀分布,这会产生更丰富的输出,因为它降低了模型重复选择最可能标记的可能性。
这种方法允许在生成过程中探索不太可能但 潜在更有趣和创造性的路径。然而,这种方法的一个缺点是,它有时会导致语法不正确或完全无意义的输出,例如every effort moves you pizza。
Top-k sampling 与概率采样和温度缩放相结合时,可以改善文本生成结果。在 top-k 采样中,我们可以将被采样的标记限制为 top-k 最有可能的标记,并通过掩盖它们的 概率得分将所有其他标记排除在选择过程之外,如图 5.15 所示。

图 5.15 使用 top-k 采样,k = 为 3,我们关注与最高 logits 相关的三个标记,并在应用 softmax 函数之前将所有其他 标记用负无穷 (-inf) 屏蔽。这导致产生一个概率分布,其中非 top-k 标记的概率值为 0。(
top-k方法将所有未选择的logits替换为负无穷值(-inf),这样在计算softmax值时,非t op-k令牌的概率得分为0,其余概率总和为1。
top_k = 3
top_logits, top_pos = torch.topk(next_token_logits, top_k)
print("Top logits:", top_logits)
print("Top positions:", top_pos)
## output
Top logits: tensor([6.7500, 6.2800, 4.5100])
Top positions: tensor([3, 7, 0])
随后,我们应用PyTorch的where函数,将我们前三个选择中低于最低logit值的标记的l ogit值设置为负无穷(-inf):
new_logits = torch.where(
condition=next_token_logits < top_logits[-1],
input=torch.tensor(float("-inf")),
other=next_token_logits
)
print(new_logits)
## output
tensor([4.5100, -inf, -inf, 6.7500, -inf, -inf, -inf, 6.2800, -inf])
最后,我们将应用softmax函数将这些转化为下一个标记的概率:
topk_probas = torch.softmax(new_logits, dim=0)
print(topk_probas)
## output
tensor([0.0615, 0.0000, 0.0000, 0.5775, 0.0000, 0.0000, 0.0000, 0.3610, 0.0000])
我们现在可以应用温度缩放和多项式函数进行概率采样,从这三个非零概率分数中选 择下一个令牌以生成下一个令牌。我们接下来通过修改文本生成函数来实现这一点。
Modifying the text generation function
现在,让我们结合温度采样和top-k采样来修改我们之前用于通过LLM生成文本的gener atetextsimple函数,创建一个新的生成函数。
def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None):
# For-loop is the same as before: Get logits, and only focus on last time step
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
# New: Filter logits with top_k sampling
if top_k is not None:
# Keep only top_k values
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(logits < min_val, torch.tensor(float("-inf")).to(logits.device), logits)
# New: Apply temperature scaling
if temperature > 0.0:
logits = logits / temperature
# Apply softmax to get probabilities
probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
# Sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
# Otherwise same as before: get idx of the vocab entry with the highest logits value
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
if idx_next == eos_id: # Stop generating early if end-of-sequence token is encountered and eos_id is specified
break
# Same as before: append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
return idx
现在让我们看看这个新的生成函数是如何工作的:
torch.manual_seed(123)
token_ids = generate(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer),
max_new_tokens=15,
context_size=GPT_CONFIG_124M["context_length"],
top_k=25,
temperature=1.4
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
## output
Output text:
Every effort moves you stand to work on surprise, a one of us had gone with random-
正如我们所看到的,生成的文本与我们通过generate_simple函数之前生成的文本非常不同("Every effort moves you know," was one of the axioms he laid...! )这是来自训练集的一个记忆段落。