Pretraining GPT model with unlabeled data 4. Load and save model weights
Loading and saving model weights in PyTorch
图 5.16 在训练和检查模型后,保存模型通常是有帮助的,以便我们可以在稍后使用或继续训练它(步 骤 6)。
到目前为止,我们已经讨论了如何数值评估训练进度以及从头开始对LLM进行预训练 。尽管LLM和数据集都相对较小,但这个练习显示出预训练LLM在计算上是很昂贵的 。因此,能够保存LLM是重要的,这样我们在新的会话中想要使用它时就不必每次都 重新运行训练。
好吧,让我们讨论如何保存和加载预训练模型,如图5.16所示。稍后,我们将从OpenAI加载一个更强大的预训练GPT模型到我们的GPTModel实例中。
幸运的是,保存 PyTorch 模型相对简单。推荐的方法是使用 torch.save 函数保存模型 的 state_dict,这是一个将每个层映射到其参数的字典:
torch.save(model.state_dict(), "model.pth")
"model.pth" 是保存 state_dict 的文件名。 .pth 扩展名是 PyTorch 文件的惯例,尽管我们在技术上可以 使用任何文件扩展名。
然后,在通过 state_dict 保存模型权重后,我们可以将模型权重加载到新的 GPTMo del 模型实例中:
model = GPTModel(GPT_CONFIG_124M)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.load_state_dict(torch.load("model.pth", map_location=device, weights_only=True))
model.eval();
像之前讨论的, dropout通过在训练过程中随机“丢弃”一层的神经元来帮助防止模型对训练数据的过拟合。然而,在推断期间,我们不希望随机丢失网络所学到的任 何信息。使用model.eval()将模型切换到推断的评估模式,禁用模型的dropout层。如果我们计划稍后继续对模型进行预训练,例如使用我们在本章早些时候定义的trainmodelsimple函数,保存优化器状态也是推荐的。
自适应优化器如 AdamW 为每个模型权重存储额外的参数。AdamW 使用历史数据动态调整每个模型参数的学习率。没有它,优化器会重置,模型可能会学习不佳,甚至无法正确收敛,这意味着它会失去生成连贯文本的能力。使用 torch.save,我们可以 保存模型和优化器的 state_dict 内容:
torch.save({
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
},
"model_and_optimizer.pth"
)
然后我们可以通过首先使用 torch.load 加载保存的数据,然后使用 loadstatedict 方法 来恢复模型和优化器的状态:
checkpoint = torch.load("model_and_optimizer.pth", weights_only=True)
model = GPTModel(GPT_CONFIG_124M)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0005, weight_decay=0.1)
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
model.train();
Loading pretrained weights from OpenAI
之前,我们使用一个包含短篇小说书籍的有限数据集训练了一个小型GPT-2模型。这种方法使我们能够专注于基础知识,而无需大量的时间和计算资源。
幸运的是,OpenAI公开分享了他们的GPT-2模型的权重,从而消除了自己在大型语料库上重新训练模型所需投入数万到数十万美元的必要。因此,让我们将这些权重加载到我们的GPTModel类中,并使用该模型进行文本生成。在这里,weights指的是存储在PyTorch的线性层和嵌入层的.weight属性中的权重参数。
例如,我们在训练模型时通过model.parameters()访问它们。在第6章中,我们将重用这些预训练权重来微调模型以完成文本分类任务,并遵循类似于ChatGPT的指示。
直接从本章的在线仓库下载gpt_download.py Python模块:
# Relative import from the gpt_download.py contained in this folder
from gpt_download import download_and_load_gpt2
执行此代码会下载与124M参数GPT-2模型相关的以下七个文件:
File already exists and is up-to-date: gpt2/124M/checkpoint
File already exists and is up-to-date: gpt2/124M/encoder.json
File already exists and is up-to-date: gpt2/124M/hparams.json
File already exists and is up-to-date: gpt2/124M/model.ckpt.data-00000-of-00001
File already exists and is up-to-date: gpt2/124M/model.ckpt.index
File already exists and is up-to-date: gpt2/124M/model.ckpt.meta
File already exists and is up-to-date: gpt2/124M/vocab.bpe
假设之前代码的执行已经完成,让我们检查一下 settings 和 params 的内容:
print("Settings:", settings)
print("Parameter dictionary keys:", params.keys())
## output
Settings: {'n_vocab': 50257, 'n_ctx': 1024, 'n_embd': 768, 'n_head': 12, 'n_layer': 12}
Parameter dictionary keys: dict_keys(['blocks', 'b', 'g', 'wpe', 'wte'])
设置和参数都是 Python 字典。设置字典存储 LLM 架构设置,类似于我们手动定义的 GPTCONFIG124M 设置。
参数字典包含实际的权重张量。请注意,我们只打印了字典的键,因为打印权重内容会占用太多屏幕空间;然而,我们可以通过打印整个字典 (使用 print(params))或通过各自的字典键选择单独的张量来检查这些权重张量,例如,嵌入层权重:
print(params["wte"])
print("Token embedding weight tensor dimensions:", params["wte"].shape)
## output
[[-0.11010301 -0.03926672 0.03310751 ... -0.1363697 0.01506208
0.04531523]
[ 0.04034033 -0.04861503 0.04624869 ... 0.08605453 0.00253983
0.04318958]
[-0.12746179 0.04793796 0.18410145 ... 0.08991534 -0.12972379
-0.08785918]
...
[-0.04453601 -0.05483596 0.01225674 ... 0.10435229 0.09783269
-0.06952604]
[ 0.1860082 0.01665728 0.04611587 ... -0.09625227 0.07847701
-0.02245961]
[ 0.05135201 -0.02768905 0.0499369 ... 0.00704835 0.15519823
0.12067825]]
Token embedding weight tensor dimensions: (50257, 768)
我们通过 download 和 loadgpt2(model_size="124M", ...) 设置下载并加载了最小的 GP T-2 模型的权重。OpenAI 还分享了更大模型的权重:355M、774M 和 1558M。这些不 同大小的 GPT 模型的整体架构是相同的.
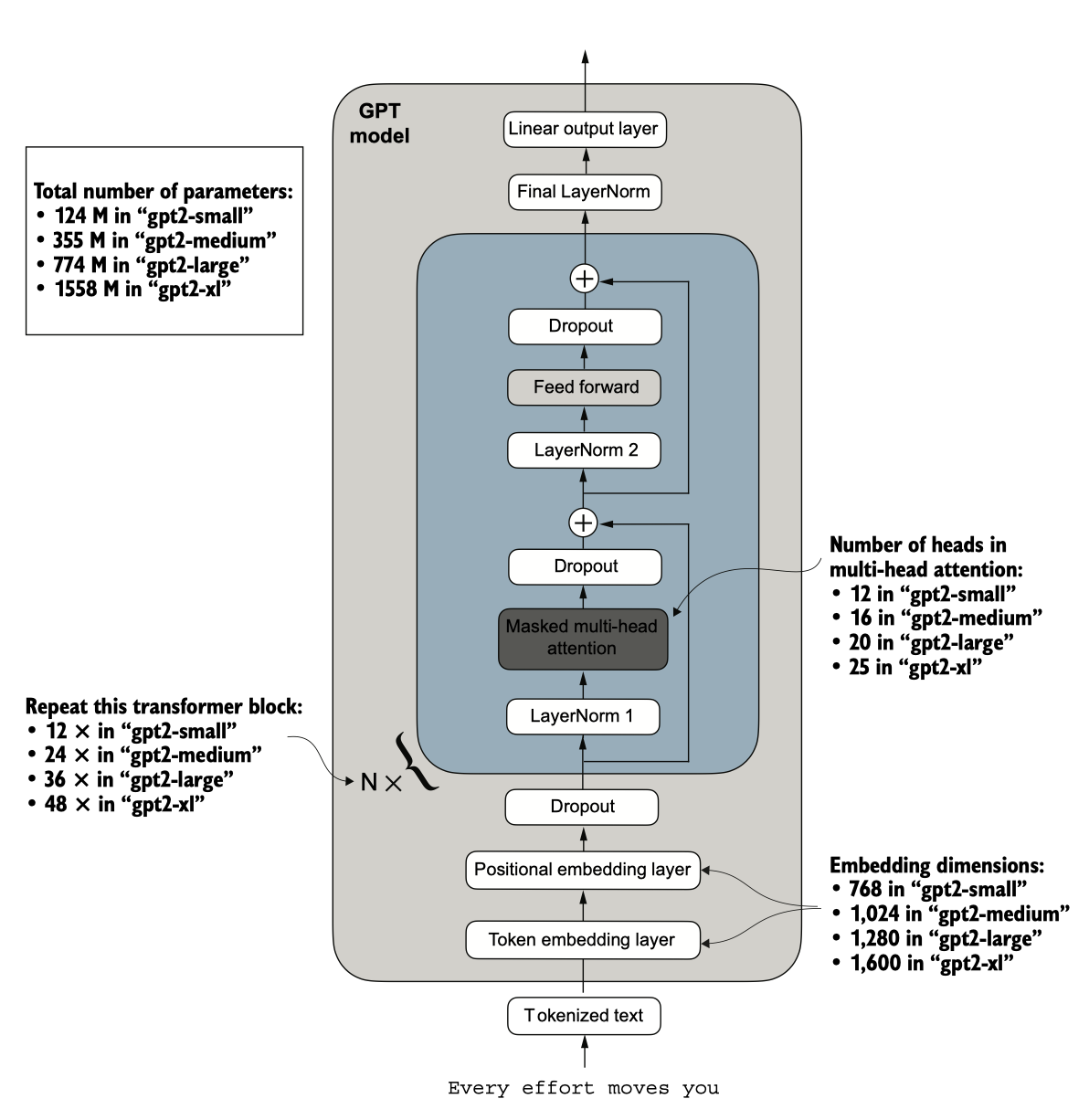
图 5.17 GPT-2 LLM 有多种不同的模型大小,参数范围从 1.24 亿到 15.58 亿。核心架构相同,唯一的区别在于嵌入大 小以及单个组件如注意力头和变换器块的重复次数。
在将 GPT-2 模型权重加载到 Python 中后,我们仍然需要将它们从设置和参数字典 传输到我们的 GPTModel 实例中。首先,我们创建一个字典,列出图 5.17 中不同 GPT 模型大小之间的差异.
假设我们有兴趣加载最小的模型“gpt2-small (124M)”。我们可以使用模型配置表中 的相应设置来更新我们之前定义和使用的全长 GPTCONFIG124M:
仔细的读者可能会记得我们之前使用了256个标记的长度,但OpenAI的原始GPT-2模型 是使用1,024个标记的长度进行训练的,因此我们必须相应地更新NEW_CONFIG.
此外,OpenAI在多头注意力模块的线性层中使用了偏置向量来实现查询、键和值矩阵的计算。在大型语言模型(LLMs)中,偏置向量不再常用,因为它们并没有改善建模性能,因此是不必要的。然而,由于我们正在使用预训练权重,我们需要匹配设置以保持一致性并启用这些偏置向量.
Load Config
我们现在可以使用更新后的 NEW_CONFIG 字典来初始化一个新的 GPTModel 实例:
# Define model configurations in a dictionary for compactness
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
# Copy the base configuration and update with specific model settings
model_name = "gpt2-small (124M)" # Example model name
NEW_CONFIG = GPT_CONFIG_124M.copy()
NEW_CONFIG.update(model_configs[model_name])
NEW_CONFIG.update({"context_length": 1024, "qkv_bias": True})
gpt = GPTModel(NEW_CONFIG)
gpt.eval();
Compare shape
默认情况下,GPTModel 实例使用随机权重进行预训练。使用 OpenAI 的模型权重的最后一步是用我们加载到 params 字典中的权重覆盖这些随机权重。为此,我们将首先定义一个小的赋值实用函数,用于检查两个张量或数组(左侧和右侧)是否具有相同的维度或形状,并将右侧张量作为可训练的 PyTorch 参数返回:
def assign(left, right):
if left.shape != right.shape:
raise ValueError(f"Shape mismatch. Left: {left.shape}, Right: {right.shape}")
return torch.nn.Parameter(torch.tensor(right))
Load Weights
接下来,我们定义一个 loadweightsinto_gpt 函数,该函数将 params 字典中的权重加 载到 GPTModel 实例 gpt 中。
import numpy as np
def load_weights_into_gpt(gpt, params):
gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])
gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])
for b in range(len(params["blocks"])):
q_w, k_w, v_w = np.split(
(params["blocks"][b]["attn"]["c_attn"])["w"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.weight = assign(
gpt.trf_blocks[b].att.W_query.weight, q_w.T)
gpt.trf_blocks[b].att.W_key.weight = assign(
gpt.trf_blocks[b].att.W_key.weight, k_w.T)
gpt.trf_blocks[b].att.W_value.weight = assign(
gpt.trf_blocks[b].att.W_value.weight, v_w.T)
q_b, k_b, v_b = np.split(
(params["blocks"][b]["attn"]["c_attn"])["b"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.bias = assign(
gpt.trf_blocks[b].att.W_query.bias, q_b)
gpt.trf_blocks[b].att.W_key.bias = assign(
gpt.trf_blocks[b].att.W_key.bias, k_b)
gpt.trf_blocks[b].att.W_value.bias = assign(
gpt.trf_blocks[b].att.W_value.bias, v_b)
gpt.trf_blocks[b].att.out_proj.weight = assign(
gpt.trf_blocks[b].att.out_proj.weight,
params["blocks"][b]["attn"]["c_proj"]["w"].T)
gpt.trf_blocks[b].att.out_proj.bias = assign(
gpt.trf_blocks[b].att.out_proj.bias,
params["blocks"][b]["attn"]["c_proj"]["b"])
gpt.trf_blocks[b].ff.layers[0].weight = assign(
gpt.trf_blocks[b].ff.layers[0].weight,
params["blocks"][b]["mlp"]["c_fc"]["w"].T)
gpt.trf_blocks[b].ff.layers[0].bias = assign(
gpt.trf_blocks[b].ff.layers[0].bias,
params["blocks"][b]["mlp"]["c_fc"]["b"])
gpt.trf_blocks[b].ff.layers[2].weight = assign(
gpt.trf_blocks[b].ff.layers[2].weight,
params["blocks"][b]["mlp"]["c_proj"]["w"].T)
gpt.trf_blocks[b].ff.layers[2].bias = assign(
gpt.trf_blocks[b].ff.layers[2].bias,
params["blocks"][b]["mlp"]["c_proj"]["b"])
gpt.trf_blocks[b].norm1.scale = assign(
gpt.trf_blocks[b].norm1.scale,
params["blocks"][b]["ln_1"]["g"])
gpt.trf_blocks[b].norm1.shift = assign(
gpt.trf_blocks[b].norm1.shift,
params["blocks"][b]["ln_1"]["b"])
gpt.trf_blocks[b].norm2.scale = assign(
gpt.trf_blocks[b].norm2.scale,
params["blocks"][b]["ln_2"]["g"])
gpt.trf_blocks[b].norm2.shift = assign(
gpt.trf_blocks[b].norm2.shift,
params["blocks"][b]["ln_2"]["b"])
gpt.final_norm.scale = assign(gpt.final_norm.scale, params["g"])
gpt.final_norm.shift = assign(gpt.final_norm.shift, params["b"])
gpt.out_head.weight = assign(gpt.out_head.weight, params["wte"])
在 loadweightsintogpt 函数中,我们仔细地将 OpenAI 实现中的权重与我们的 GPTM odel 实现进行了匹配。作为一个具体的例子,OpenAI 将第一个变换器块的输出投影层
的权重张量存储为 params["blocks"][0]["attn"]["cproj"]["w"]。在我们的实现中,这个权重张量对应于 gpt.trfblocks[b].att.outproj.weight,其中 gpt 是一个 GPTModel 实例 。
开发 loadweightsinto_gpt 函数花费了很多猜测时间,因为 OpenAI 使用了与我们稍微不同的命名约定。然而,如果我们尝试匹配两个维度不同的张量,assign 函数会提醒我们。此外,如果我们在此函数中犯了错误,我们会注意到这一点,因为生成的 GPT 模型将无法产生连贯的文本。
现在我们来实践一下 loadweightsinto_gpt,并将 OpenAI 模型权重加载到我们的 G PTModel 实例 gpt 中:
load_weights_into_gpt(gpt, params)
gpt.to(device);
Test Genearte Text
如果模型加载正确,我们现在可以使用之前的生成函数来生成新文本.
torch.manual_seed(123)
token_ids = generate(
model=gpt,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(device),
max_new_tokens=25,
context_size=NEW_CONFIG["context_length"],
top_k=50,
temperature=1.5
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
## output
Output text:
Every effort moves you toward finding an ideal new way to practice something!
我们可以确信我们正确加载了模型权重,因为模型能够生成连贯的文本。在这个过程中出现一个微小的错误会导致模型失败。在接下来的章节中,我们将进一步使用这个预训练模型,并对其进行微调,以对文本进行分类和遵循指令。
Summary
- 当大型语言模型(LLM)生成文本时,它一次输出一个token。
- 默认情况下,下一个token是通过将模型输出转换为概率分数,并选择与最高概率分数对应的词汇中的token,这种方法称为“greedy decoding”。
- 通过概率采样(probabilistic sampling)和温度调整(temperature scaling),我们可以影响生成文本的多样性和一致性。
- 在训练过程中,可以使用训练集和验证集的损失(losses)来评估LLM生成文本的质量。
- 预训练LLM是通过调整其权重来最小化训练损失。
- LLM的训练循环本身是深度学习中的标准流程,使用常规的交叉熵损失和AdamW优化器。
- 在大规模文本语料上对LLM进行预训练既耗时又耗资源,因此我们可以加载公开可用的权重,作为不自己在大型数据集上预训练模型的替代方案。